Monday 2026-08-03
12:00 AM
The Rowboat [Seth Godin's Blog on marketing, tribes and respect]
“Working in the studio is like building a ship in a bottle. Playing live is like being on a rowboat in the ocean.” Jerry Garcia
You probably need some studio time, but you definitely need to play live.
Sunday 2026-08-02
11:00 PM
04:00 PM
Kanji of the Day: 届 [Kanji of the Day]
届
✍8
小6
deliver, reach, arrive, report, notify, forward
カイ
とど.ける -とど.け とど.く
届け (とどけ) — report
届け出 (とどけで) — report
届く (とどく) — to reach
届ける (とどける) — to deliver
婚姻届 (こんいんとどけ) — marriage registration
被害届 (ひがいとどけ) — filing a (criminal) complaint
届出 (とどけで) — report
不届き (ふとどき) — outrageous
届け出る (とどけでる) — to report
無届け (むとどけ) — without notice
Generated with kanjioftheday by Douglas Perkins.
Kanji of the Day: 簿 [Kanji of the Day]
簿
✍19
中学
register, record book
ボ
名簿 (みょうぶ) — proof of identity (for nobles, doctors, etc.; Heian period)
家計簿 (かけいぼ) — household account book
簿記 (ぼき) — journalization (accounts)
帳簿 (ちょうぼ) — account book
選挙人名簿 (せんきょにんめいぼ) — voter registration list
候補者名簿 (こうほしゃめいぼ) — list of candidates
通信簿 (つうしんぼ) — report card
簿価 (ぼか) — book value
登記簿 (とうきぼ) — register
簿外 (ぼがい) — unaccounted
Generated with kanjioftheday by Douglas Perkins.
12:00 PM
Just for Skeets and Giggles (8.1.26) [The Status Kuo]
Before we jump in, a little housekeeping. Some readers report they're having trouble opening X-based video files, for which I use Xcancel links to avoid sending traffic to that site. This seems especially true for users accessing the links via iPads. In my tests, mobile phones seem to load the videos fine, while iPads load them slowly or not at all. I recommend using a mobile phone for best viewing! If a video won’t load for you, try copying and pasting the link into your browser (Chrome or Safari only). I will also include the source link after each video for your convenience. It should load faster, though it will direct you to X.
Also, July was the second month in a row that I lost more paid supporters than I gained. Sadly, that's not sustainable. If you have been enjoying my work for some time and would like to help staunch the bleeding, please consider upgrading to a paid account if you haven’t already. Your support allows me to continue offering this for free to those on fixed income or disability. Thanks!
Now, on to the funnies!
The White House Correspondents’ Dinner had a do-over this week, but Trump quickly regretted attending.

(Source)
And that’s not even counting how badly he bombed trying to tell jokes. Jon Stewart with some advice.

(Source)
Trump also attacked Kaitlan Collins at the dinner. But it doesn’t seem to have fazed her.

Jimmy Fallon has a running gag about all the words Trump can’t seem to pronounce anymore as dementia encroaches.

(Source)
Trump also can’t get his pop culture references right, prompting someone behind him to give a memorable impression.

(Source)
When Trump manages to speak without bombing or stumbling, what comes out is often quite something.

(Source)
The corruption at the White House is now out in the open.

And when he’s not stealing, conning or grifting, Trump is, well, asleep.

The afterlife is beckoning!

(Source)
“Incontinentia Buttocks” was a character from Monty Python’s Life of Brian, but we appear to be living it. One poor man, perhaps a part of his Secret Service detail, had to suffer through it.

(Source)
The freeze frames tell the story.

The guy next to him noticed something off, too.
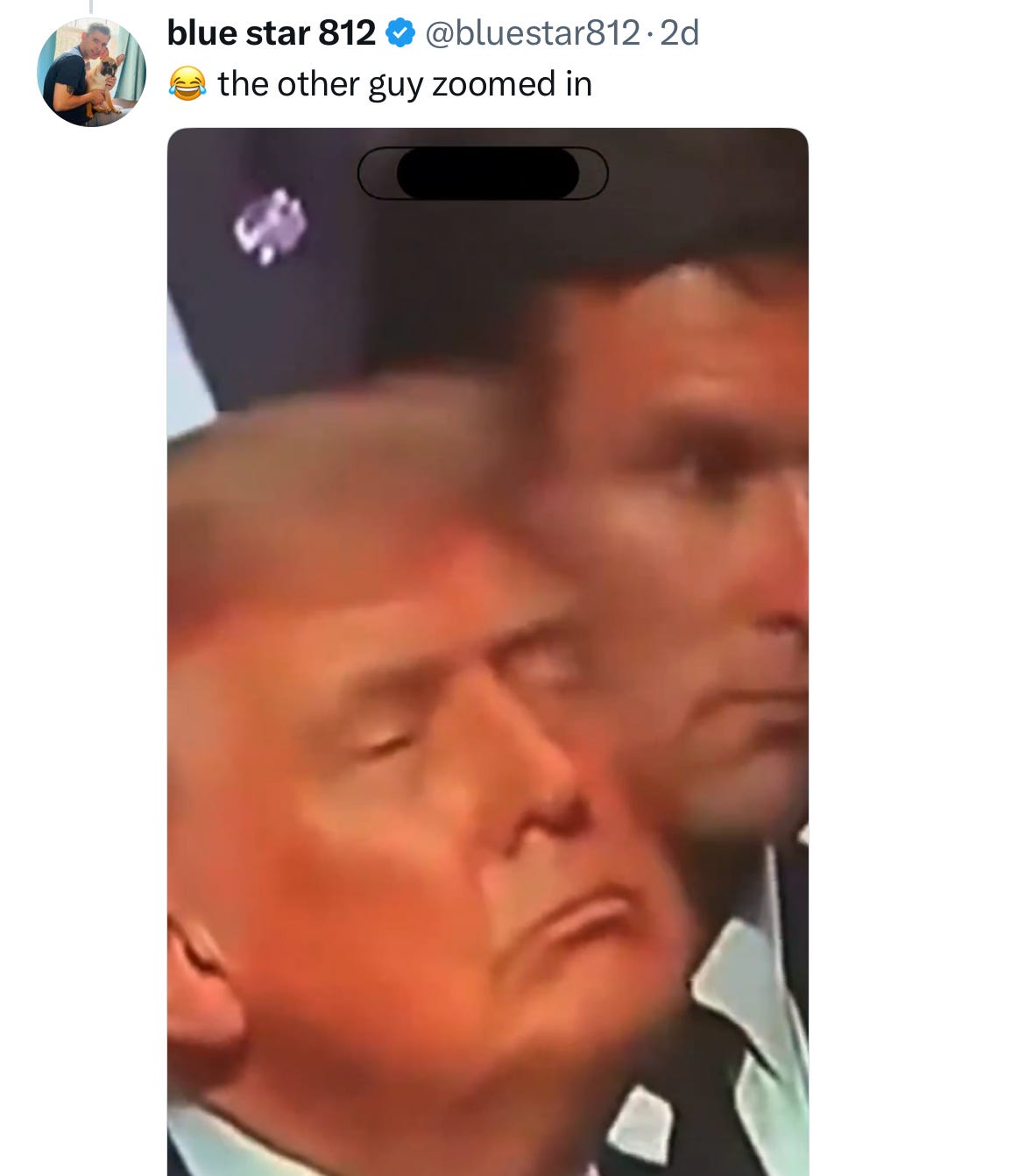
(Source)
We all need this energy.

Or as Rosie O’Donnell put it, after the president once again attacked her personally,

(Source)
On policy, the Trump White House continues to mystify while failing spectacularly.

Meanwhile, the GOP, and particularly Rand Paul and his conspiracy theories, devotes its time to attacking Dr. Anthony Fauci. I concur with this sentiment.

Borowitz with the three-pointer.

Perhaps there’s a side benefit to Paul releasing the Fauci diaries he somehow got his red-pill stained hands on.

Gavin Newsom with the layup.

Paul decided to go live on the air with callers, which is never a good idea when you’re this hated.

In Fauci’s honor, remember this amazing moment? It’s probably why Trump turned on him.

The best takedown came from The Daily Show. It’s Laura Ingraham on, well, Laura Ingraham.

(Source)
This group hates Fauci but reveres RFK Jr.

When a MAGA relation or associate texts you with their nonsense, here’s how to troll them. I’m truly impressed.

We’re still wondering whether McConnell is being propped up by his handlers.

The Beaverton with the brutal headline.

Or as someone else put it,

The DOJ dropped its case against former Olympian David Hearn after insisting for weeks that he had vandalized the Lincoln Memorial Reflecting Pool and smearing his good name, only to admit a botched installation caused the damage.

Lawmakers tried to ride the popularity of Nolan’s blockbuster, but some were quicker than others.

Sigh. I feel your pain, Rep. Pressley, whenever I try to be clever on social media.
Speaking of The Odyssey,

Some terminally online people (cough, Elon Musk, cough) still have their panties in a bunch over The Odyssey’s casting. Josh Johnson on the subject:

In really fun news, apparently no one is coming to rescue the Tate brothers. This community note on Andrew Tate’s heartfelt tweet to his supporters was amazing.

He hasn’t stopped complaining since he was locked up.

I aspire to this level of catty.

On to the cuties!
Give this little one all the awards.

And give this fella a little space, lol.

This is a whole mood.

(Source)
I can’t say my own corgi, Windsor, tries very hard to make friends like this with my kitty, Shade. So this was inspiring.

(Source)
I have visited Istanbul, city of cats, and would have taken 1,000 pictures of this one.

(Source)
I feel this puss represents many of us.

I just want to tell him it’s all going to be okay!

I feel this deeply as I try to juggle everything lately.

I am a bit obsessed with the little penguin chicks closest to the edge who are being crowded into taking the leap.

I can’t believe they caught this on film. Oh, my heart! Nature is amazing.

Promote whoever came up with this promo.

(Source)
“Let’s have dinner right by the water; it will be so romantic!”

(Source)
Honestly, same. You know it’s coming, but it’s still funny.

(Source)
This is totally going to happen when I leave my kids with my older brother for a few days.

His name is Mack. Mack the Knife.

(Source)
They pulled the wool over his eyes!

We close with a dad joke, from a daughter, told to the crows.

Have a great weekend!
Jay
06:00 AM
This Week In Techdirt History: July 26th – August 1st [Techdirt]
This Week in 2016
- Whether Or Not Russians Hacked DNC Means Nothing Concerning How Newsworthy The Details Are
- Verizon Buys Yahoo In $4.8 Billion Attempt To Bore The Internet To Death
- Declaring Cyberwar On Russia Because Of The DNC Hack Is A Bad Idea
- IP Lawyers Tell Copyright Office To Stop Screwing The Public By Opposing Cable Box Reform
- Intellectual Property Fun: Is Comedy Central Claiming It Owns The Character Stephen Colbert?
- The Selfie-Taking Monkey Who Has No Idea He Has Lawyers Has Appealed His Copyright Lawsuit
This Week in 2011
- The Absurdity Of Comparing Copying To Stealing
- New Study: Piracy Increases The Quality Of Content
- Getting Past The Myth That Copyright Is Needed To Produce Content
- Writer Explains How Copyright Has Prevented Her From Ever Seeing TV Shows She Wrote
- UK Appeals Court Agrees That Clicking A Link And Opening A Website… Is Infringing
- Why People Pay More For Access To Infringing Content
This Week in 2006
04:00 AM
Pluralistic: Why businesses lie about AI (01 Aug 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources:
None
-->

Today's links
- Why businesses lie about AI: Humoring the boss all the way into bankruptcy.
- Hey look at this: Delights to delectate.
- Object permanence: Vinge x NYT; Syklarov x publishers; Human hair castles; Gingrich's bot army; Accessibility v Web DRM; David Byrne x WinXP; Furries don't fuck in fursuits; AI's pogo-stick grift.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Why businesses lie about AI (permalink)
Neoclassical economics assumes rationality. The corollary of, "If you're so smart, why aren't you rich?" is "you're rich, so you must be very smart!" Thus it is that many people assume that if powerful, well-compensated CEOs insist that "AI is changing everything," well then, AI must be changing everything.
But the evidence for this "changing everything" thesis is thin on the ground. Despite a global mania that has reduced the real, pressing need for digital sovereignty to the imaginary need to create "sovereign AI," no one can really articulate the case for "sovereign AI." If Donald Trump ordered Big Tech to turn off all of your country's chatbots tomorrow, nothing would change. Every one of your country's ministries and corporations would chug on with nary a hitch. Households, too, though perhaps a few of the younger members of those families would have to do their own homework again.
(Contrast this with what would transpire if Trump directed his tech giants to switch off your country's Office 365 access, or to brick your Android and iOS phones, or to killswitch your John Deere tractors. Your country would effectively cease to exist. If "digital sovereignty" means anything, it means doing something about this urgent fact):
https://pluralistic.net/2026/06/18/their-trillions-our-billions/#eyes-on-the-prize
The world is full of people who insist that "AI is changing everything" but who – when pressed – have to admit that what they mean is that they're pretty sure that AI will change everything. Eventually. After we allow it to consume all the planet's energy, carbon, water and financial resources.
Maybe.
(They're pretty sure.)
One person who's had a lot of opportunity to observe the shear between the stated business/AI situation and the real business AI situation is Nikhil Suresh from Hermit Tech, a consulting firm of "radically ethical data wizards" (that is, tech consultants). Suresh reports on his experience talking with hundreds of executives (and, more importantly, their subordinates) about what (if anything) AI is doing for business in an essay entitled "AI Mania Is Eviscerating Global Decisionmaking":
https://hermit-tech.com/blog/ai-mania-is-eviscerating-global-decisionmaking
Suresh has a good track record of writing trenchant, frank criticism of AI. You may know him from his 2024 essay, "I Will Fucking Piledrive You If You Mention AI Again":
https://ludic.mataroa.blog/blog/i-will-fucking-piledrive-you-if-you-mention-ai-again/
Or possibly from his "Contra Ptacek's Terrible Article On AI," a stinging rebuttal to Thomas Ptacek's widely read "My AI Skeptic Friends Are All Nuts":
https://ludic.mataroa.blog/blog/contra-ptaceks-terrible-article-on-ai/
While those are important pieces of critical AI realpolitik, none of them have the heft or urgency of "AI Mania Is Eviscerating Global Decisionmaking," whose thesis can be summed up with this passage from halfway through this 6,000-word article:
[W]e’re facing a coordination problem around executives being honest around the AI gains they’ve witnessed – if they co-operate, they keep their jobs. If they defect, they will possibly be fired by their embarrassed peers (who have now been implicitly called liars, cowards, or incompetents) and then replaced with someone that will toe the line anyway. If they could all admit the truth at once there might be some hope, but there is no way to coordinate that event.
In other words, corporate leadership is starting from the premise that AI has (or will) radically change the business, and they're working backwards from that premise to find the evidence to support this article of faith.
In support of this thesis, Suresh cites "hundreds" of conversations with execs and employees who spoke to him on the condition that he would "file the serial numbers" off their stories. These, combined with his own experience consulting for large, multi-billion-dollar companies make it clear that "AI mania" is an absolutely justifiable label for the state of AI in corporate circles.
Here are a few highlights from this morning's read – moments where I had to look away from my screen and read out a passage to my wife so that we could share a "holy shit" moment.
A person worked for a division that "pivoted" to re-engineer its software to create interfaces that support AI agents. When it became apparent that only ten users had touched this expensive new technology, they "pivoted" again to support "agentic workflows." Why did they double down on AI agents after discovering such yawning market indifference for "agentic"? "Because every company has to do something agentic now."
Suresh describes this as a literal religious mania. In the 500+ employee businesses Suresh studied, the only people who were promoted – or even spared from being fired – were people who professed "religious declarations of faith" about "the transformative power of AI." Employees who voiced honest, informed objections to AI in the workplace were passed over for promotions or targeted for layoffs.
This has created a situation in which everyone – "boards, executives, employees, vendors, consultants" – has a strong incentive to lie about how much AI is delivering for their companies. Suresh says he's seen announcements from publicly traded companies about their AI triumphs that he knows for a fact never took place.
Suresh says he's never seen a successful enterprise AI project: "Every single one – we have seen 0% success in a year and a half." Not one of their clients would face a business challenge if OpenAI went out of business tomorrow. The problem most companies struggle with is that they're "terminally bad at running software projects effectively." Adding AI to the mix doesn't solve this problem – it just adds a whole new range of ways that software deployment can fail.
Chatbots don't help. The internally facing chatbot that's supposed to help employees figure out how to navigate the business sucks because it is only as good as its training data – the business's documentation of its own processes. Businesses suck at documenting their processes. Customer-facing chatbots also suck. They either can't solve your problem, or, when they seem to solve your problem, the "solution" goes nowhere.
Suresh recounts his sole positive customer service chatbot experience: a Mitsubishi chatbot with a natural sounding, responsive voice politely took all the details of an automotive failure and promised him a callback. That callback never came, but Suresh is certain that Mitsubishi has logged this as a chatbot success story, even though the experience convinced him not to buy a Mitsubishi car.
Suresh and his team at Hermit Tech now have a policy of not even asking about ongoing AI projects. They've learned that by the time an AI project has begun, no one will discuss it honestly until it reaches a crisis point.
Suresh says he frequently encounters people who reflexively utter the AI catechism: "AI is changing everything." But when he presses these people for details, they admit that their organization "does not currently use LLMs for anything, and indeed, that they cannot name a single thing that has changed other than they get some use out of ChatGPT."
This shear ("AI is changing everything"/"Well, OK, we're not using AI for anything") is so extreme that Suresh once met an exec who confessed to crafting an AI-centered AI strategy for a $2b/year business, even though that exec "had never even used ChatGPT or any AI tool in their life."
Some people have privately admitted to Suresh that they've embraced AI in order to earn a career-boosting corporate reputation for "thought leadership." But many other people (especially nontechnical people) sincerely believe that AI is about to "change everything." As Suresh says, if you're in business with a liar, you might be able to reason with them in private – but you can't reason with a true believer.
The true believers are in charge. Suresh points out that it would be very weird for the CEO of an engineering firm or a hospital to mandate "specific procedures or building techniques without explicit agreement from the professionals on staff." But when it comes to AI, business leaders will confidently demand that the skilled professionals who perform the business's core functions use AI, even if those professionals don't think it will help.
As an aside: I remember the dotcom era, when the business press was full of articles about the conflict between CEOs and a new workforce that demanded the right to use the web on the job. Today, the business press is full of articles about the conflict between the workforce and CEOs who demand that they use AI.
Suresh describes workers who feel they have to "AI wash" their work: "They just do the work, the same way they have for decades, and say Claude did it." To add verisimilitude to this sham, they write circular processes in which one chatbot prompts another, and then the process repeats itself in reverse, for the sole purpose of consuming AI tokens to score a high rank on corporate "token leaderboards."
How to account for this wildly, expensively irrational corporate leadership? Suresh places the blame in the hypnotizing, mesmerizing power of the AI demo. For example: Hermit Tech is often engaged to set up a database product called Snowflake for its customers. Snowflake has a useless, expensive AI bolt-on called Cortex, that Snowflake itself describes as being 92% accurate under ideal circumstances (that is, at least 8% of the time, it will mislead you, perhaps very badly).
Suresh describes sales meetings with execs who were lukewarm on the idea of retooling with Snowflake, but who were very interested in Cortex. Against their better judgment, Suresh and his team provided them with a Cortex demo, carefully explaining that this AI tool could not satisfy their requirements. Without fail, this resulted in the previously lukewarm customers insisting that they be allowed to purchase Cortex immediately. Sales prospects who'd been unmoved by a pitch for new technology that would result in millions in savings were hypnotized by demos of a product that was described as unsuitable and unreliable.
To their credit, Hermit Tech refused to sell these customers Cortex, and stopped doing Cortex demos altogether. Suresh describes the experience of "the total 180°, that shift from ice-cold to red-hot buying frenzy" as "deeply unsettling." What's more, the Cortex demos that Suresh and co performed were, by his account, pretty uninspiring. The thing that these demos had going for them is that they showed AI actually doing something marginally useful, to execs who'd already spent millions on AI without having anything to show for their money. The spectacle of AI that does something galvanizes corporate leaders who feel like they're the only bosses who can't find a revolutionary use for AI in their businesses.
This is the situation up and down the corporate org-chart. Suresh has a reader whose title is "Head of AI" at a billion-dollar firm who tells him "their job is totally fraudulent but it was the only promotion pathway remaining at the organisation." This exec is hardly alone. They're part of a cohort of executives at companies that have publicly announced "100x" productivity gains, but who confessed to Suresh that nothing of the sort has happened.
Why did these companies make these claims? Because their customers were making the claims. How could you hope to sell to a company that had 100x'ed its productivity with AI unless you, too had 100x'ed your productivity? If, as a vendor, you walked into a boardroom and said that this wasn't a plausible claim, you'd be calling your sales prospect a liar, with real consequences: "getting enterprise contracts cancelled because you wanted to opine on something that doesn’t really matter to your organisation’s mission is a great way to get fired."
With the state of the industry dominated by froth, lies and mutual destruction pacts, it's no wonder that companies are deploying "totally gameable metrics such as 'money spent on AI'" as a means of evaluating employees and divisions.
Between true believers and people who must find ways to plausibly tout their AI usage, there is now a gigantic market for "AI solutions." At best these are just traditional tech consulting contracts, like migrating a database from Oracle to Snowflake, with some kind of ornamental AI usage around the edges so that the person who commissions the work can claim to be "procuring AI-enabled services" for the business.
This isn't a harmless frippery: contracts are delayed and work is put off until the work can be made "sufficiently AI" to attain the minimum degree of buzzword compliance. Worse: every fake AI project that produces real results (because it's not really AI) adds credibility to the AI true believers, who view these projects as proof that AI can do anything, and therefore demand to know why everything isn't being done by AI.
Suresh ends his essay with a long section on how to "navigate AI mania" – advice for how to smile and nod politely when you're confronted with AI bullshit, while steering clear of the worst consequences and avoiding needless fights. This looks like very sound advice for anyone in a corporate environment, but thankfully, that isn't me.
Rather than summarize that advice, I want to reflect a little on two questions that Suresh's essay raises but doesn't answer. The first is why? Why are people in power such easy converts to this religious mania?
I have my own theory. The most important discomfort that powerful people experience is having ego-shattering conflicts with subordinates who know how to do things they do not know how to do. The fact that you're "in charge" is hard to reconcile with the fact that the people you're nominally in charge of tell you that all your ideas are impossible, illegal, immoral, or lethal:
https://pluralistic.net/2026/01/05/fisher-price-steering-wheel/#billionaire-solipsism
Take that Cortex demo. Sure, Cortex is an expensive, unreliable way to address a Snowflake database. But (unlike Snowflake) Cortex is controlled via conversational, plain-language commands. With Cortex, a boss doesn't need to ask an underling to retrieve information from the company Snowflake system, an interaction that might come with unsolicited feedback about the technical or commercial incoherence of the boss's request. Cortex is the underling, except that unlike a human underling, Cortex never back-sasses you about your foolish questions. The fact that it grossly misleads you 8% of the time is a small price to pay for a life untroubled by uppity pismires who insist that your ideas be connected to base reality as they understand it.
The other question Suresh implicitly raises is, "How can you reconcile the failure of AI in the enterprise with the individual claims of skilled technologists who insist that AI is helping them do great work?" The answer is that these AI users are "centaurs" – experienced workers who are assisted by automation on terms that they set for themselves:
https://pluralistic.net/2025/09/11/vulgar-thatcherism/#there-is-an-alternative
Thanks to their skill and experience, these workers possess discernment, the ability to tell good code from bad, and (more importantly) good uses of code-generation tools from bad. They demonstrate the adage that worker-driven automation improves quality, while capital-driven automation improves throughput:
https://pluralistic.net/2026/07/28/hitl-ers/#ai-ai-oh
An automation technique that requires close supervision by skilled and experienced workers isn't going to be a raw productivity powerhouse. You don't "100x" your code this way, at least, not in the sense of firing 99 of your coders and having the remaining programmer pick up all their work. Rather, an automation tool that requires the continuous and conscientious exercise of discernment will let individual practitioners improve their work in extremely satisfying and useful ways. It's a way to spend more on operations in order to produce better outputs. It's not a way to cut your workforce, realize a gigantic savings, and still produce comparable goods and services at a far lower cost.
That is why some individual coders report such delight with their AI tools. They engage with those tools on their own terms, to improve their work in the ways that they, in their expert judgment, consider beneficial. No one ranks them on a "token-maximization" scoreboard. No one tells them they can't do a project if it isn't "sufficiently AI." When they set out to do a project, no one makes them prove that it couldn't be "done by AI."
As ever, the most important fact about a given technology isn't "what it does," but "who it does it for" and "who it does it to."
All the pathologies Suresh observes and documents so well in this piece are hypertrophied versions of the buzzword-compliance dysfunctions from previous bubbles, but at a scale never before seen. Quantity has a quality all its own. These businesses aren't just wasting billions – they're replacing skilled workers with defective chatbots. As I've written before, AI is the asbestos we're shoveling into the walls of our technological society. Our descendants will spend generations digging it out again, and the longer the bubble goes on without popping, the longer it will take to repair the damage.
Hey look at this (permalink)

- The rent was already high. Then came the $200 work-from-home fee https://finance.yahoo.com/real-estate/articles/rent-already-high-then-came-174555709.html
-
Families in London temporary housing told they cannot use in-built air conditioning https://www.theguardian.com/society/2026/jul/27/homeless-families-london-temporary-housing-air-conditioning
-
The New Defcon Badges Pack a Unique Open Source Chip That Doubles as a Security Key https://www.wired.com/story/defcon-34-badge-baochip-andrew-bunnie-huang/
-
US government map of Africa mislabels every country at global conference https://www.theguardian.com/us-news/2026/jul/30/government-map-mislabels-african-countries?CMP=Share_AndroidApp_Other
-
EFF Guide to Recording Law Enforcement https://www.eff.org/deeplinks/2026/07/eff-guide-recording-law-enforcement

Object permanence (permalink)
#25yrsago Vernor Vinge in the NYT https://www.nytimes.com/2001/08/02/technology/a-scientist-s-art-computer-fiction.html
#25yrsago Why publishers should thank Syklarov https://web.archive.org/web/20011023092940/http://www.zdnet.com/zdnn/stories/comment/0,5859,2800985,00.html
#25yrsago David Byrne track to be bundled with WinXP https://web.archive.org/web/20010804040357/http://www.ananova.com/news/story/sm_365899.html?menu=news.technology
#20yrsago Five things about blogs that no one ever needs to say again https://web.archive.org/web/20060813090449/http://www.stevenberlinjohnson.com/2006/08/five_things_all.html
#15yrsago Castles made from human hair https://inhabitat.com/artist-uses-human-hair-to-construct-a-castle-of-3000-bricks/
#15yrsago Wisconsin Democratic voters targeted with Koch-funded absentee ballot notices advising them to vote 2 days after the recall election https://www.politico.com/blogs/david-catanese/2011/08/afp-wisconsin-ballots-have-late-return-date-037977?showall
#15yrsago Gingrich’s million Twitter followers: “80% dummy accounts, 10% paid followers” https://web.archive.org/web/20110812100159/https://gawker.com/5826645/most-of-newt-gingrichs-twitter-followers-are-fake
#15yrsago Missouri State business-school professor leads successful campaign to ban Slaughterhouse-Five from local schools https://www.theguardian.com/books/2011/jul/29/slaughterhouse-five-banned-us-school
#10yrsago Australian media accessibility group raises red flag about DRM in web standards https://hotelsantalya.net/accessiq/news/news/2016-p/08-p/concerns-raised-for-assistive-technology-development-as-w3c-debates-encrypted/
#10yrsago Reminder: the GOP has been attacking veterans and their families for years https://web.archive.org/web/20160803203106/https://crookedtimber.org/2016/08/02/trumps-indecent-proposal/
#10yrsago Isis joins Donald Trump in denouncing Khizr Khan https://web.archive.org/web/20160802161454/https://theintercept.com/2016/08/02/donald-trump-and-islamic-state-agree-no-room-for-people-like-khizr-khan/
#10yrsago Furries don’t have sex in fursuits https://www.ohjoysextoy.com/fursuits-grey-white/
#5yrsago Machine learning sucks at covid https://pluralistic.net/2021/08/02/autoquack/#gigo
#1yrago AI's pogo-stick grift https://pluralistic.net/2025/08/02/inventing-the-pedestrian/#three-apis-in-a-trenchcoat
Upcoming appearances (permalink)

- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/ -
Vancouver: BC Policy Solutions Gala, Nov 12
https://bcpolicy.ca/gala/

Recent appearances (permalink)
- F@#$ the AI Overlords (On The Media)
https://www.wnycstudios.org/podcasts/otm/articles/f-the-ai-overlords -
Why AI Won't Replace Workers, But Will Crash The Economy (Smart Cookies)
https://www.youtube.com/watch?v=rRRmUuxJolY -
AI and the Enshittification Era (The Weekly Show with Jon Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE

Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com

Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027

Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING

This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
Saturday 2026-08-01
11:00 PM
“Welcome back” [Seth Godin's Blog on marketing, tribes and respect]
What if they meant it?
What if your return felt special to the people behind the counter?
What if they knew, without looking it up, or being told–what if they knew that you were here, again, a vote of trust and confidence.
Returning home is one of the oldest human desires. It’s a feeling that doesn’t easily lend itself to automation, procedures, or scale.
Being welcomed home offers us dignity, safety and belonging. Hard to fake, worth working hard to create.
09:00 PM
World Cup Piracy Crackdown Shows Limits of Domain Seizures, MPA Pushes Site Blocking [TorrentFreak]
 Operation Offsides was the largest sports piracy crackdown ever carried out during a single event.
Operation Offsides was the largest sports piracy crackdown ever carried out during a single event.
From the start of the FIFA World Cup through the final, U.S. authorities and their partners seized more than 1,000 domains, while close to 2,000 more were blocked across Latin America.
The Motion Picture Association, which coordinated the effort through its Alliance for Creativity and Entertainment (ACE), previously praised the operation as a massive success. However, in an op-ed published by RealClearMarkets yesterday, MPA’s leadership admits that domain seizures have their limitations.
“It Does Not Dismantle the Business”
The op-ed, titled “Blowing the Whistle on World Cup Piracy,” is written by MPA Chairman and CEO Charles Rivkin and IPR Center Director Ivan Arvelo. It celebrates the operation as a clear success, noting that the seized sites racked up more than 156 million visits in July alone before they were taken offline.
Indeed, disrupting millions of potential visits has an impact. However, the crackdown also had its limitations, as it does not take out the operations running these sites. These limitations are also recognized in the op-ed.
“A takedown is essential, and it can interrupt access for a moment. But it does not dismantle the business behind it,” Rivkin and Arvelo write.
This is not the type of admission you expect from the MPA or the IPR Center, who just completed the largest piracy domain seizure round in U.S. history. However, the framing does nicely set up the policy argument that follows. At the same time, it corroborates our earlier coverage.
The Russian and Iranian Domains That Survived
Two weeks before the op-ed appeared, we reported that several major pirate streaming brands had switched to fallback domains on Iran’s .ir country-code TLD, in an apparent effort to move to infrastructure that is harder for U.S. law enforcement to reach.
Iranian domains have significant drawbacks of their own, especially for those operations who want to run ads, so there is no mass exodus. However, many that migrated to the .ir TLD remain online today.
A check this week shows that Buffstreams, Footybite, Totalsportek, and Nflbite brands all remain reachable on their .ir fallbacks. None have been suspended or seized, which is no surprise since Iranian authorities are not eager to cooperate with the U.S.
Meanwhile, the largest sites were never dependent on U.S.-controlled infrastructure to begin with. A popular Futbol-libres domain, for example, operating on the Russian-run .su registry, was not among the seized domains and reportedly drew more than 200 million visits in July, according to Similarweb data. That is more than the 156 million visits the MPA counted across all seized domains.
MPA Sees More Attack Vectors
While domains are just part of a site’s infrastructure, it is clear that domain seizures have their limitations. This is not news to the MPA and ACE, who are constantly tracking these domain name migrations.
Speaking with TorrentFreak, MPA’s Executive Vice President and Chief Content Protection Officer Larissa Knapp notes that these familiar tactics are not without weaknesses.
“Piracy operators regularly move domains and infrastructure in an effort to evade enforcement. The migration to .ir domains is another example of that tactic, but changing a domain does not put an illegal operation beyond reach,” Knapp says.
“These services still depend on identifiable operators, hosting, distribution, payment systems, and other technical and commercial infrastructure. That is why ACE works closely with law enforcement and industry partners around the world to identify and disrupt the people and infrastructure that keep these criminal networks operating.”
Knapp suggests that pirate sites rely on a broader infrastructure than domain names alone, so MPA and ACE try to find other weak spots to bring them down. And that’s not all.
Pirate Site Blocking as Solution
This brings us back to the op-ed, which ends with a clear policy ask. Rivkin and Arvelo argue that domain seizures alone cannot solve live sports piracy, and that the U.S. needs “every tool” available to fortify its anti-piracy work.
“Chief among them would be judicial site blocking in the U.S.,” they write, describing it as an anti-piracy tool that’s already used in nearly 60 countries.
The MPA and IPR Center heads see domain seizures as part of a broader enforcement toolbox, which should be complemented with site blocking. While Iranian and ‘Soviet Union’ domains are not mentioned, these could be key site blocking targets.
The site blocking call comes at a time when U.S. site blocking legislation is high on the political agenda again. On June 30, the House IP subcommittee held a hearing on online copyright enforcement, where Chairman Rep. Darrell Issa signaled that bipartisan, bicameral agreement was near.
Thus far, such a unified U.S. site blocking bill has yet to be introduced, but it seems to be only a matter of time. That also applies to the overblocking concerns, which will undoubtedly come, as will the eventual evasive tactics of pirates.
From: TF, for the latest news on copyright battles, piracy and more.
04:00 PM
Kanji of the Day: 菜 [Kanji of the Day]
菜
✍11
小4
vegetable, side dish, greens
サイ
な
野菜 (やさい) — vegetable
菜の花 (なのはな) — rape blossoms
白菜 (はくさい) — napa cabbage (Brassica rapa subsp. pekinensis)
山菜 (さんさい) — edible wild plants
小松菜 (こまつな) — Japanese mustard spinach (Brassica rapa var. perviridis)
総菜 (そうざい) — small dish (served as a part of an ordinary household meal)
惣菜 (そうざい) — small dish (served as a part of an ordinary household meal)
家庭菜園 (かていさいえん) — kitchen garden
前菜 (ぜんさい) — hors d'oeuvre
香菜 (こうさい) — coriander (Coriandrum sativum)
Generated with kanjioftheday by Douglas Perkins.
Kanji of the Day: 矛 [Kanji of the Day]
矛
✍5
中学
halberd, arms, festival float
ム ボウ
ほこ
矛盾 (むじゅん) — contradiction
矛先 (ほこさき) — point of a spear
自己矛盾 (じこむじゅん) — self-contradiction
論理矛盾 (ろんりむじゅん) — logical inconsistency
相矛盾 (あいむじゅん) — mutually contradictory
形容矛盾 (けいようむじゅん) — contradictio in adjecto
銅矛 (どうほこ) — bronze hoko
矛盾語法 (むじゅんごほう) — oxymoron
矛盾撞着 (むじゅんどうちゃく) — self-contradiction
矛盾律 (むじゅんりつ) — law of contradiction (logic)
Generated with kanjioftheday by Douglas Perkins.
02:00 PM
RFK Jr., Who Is Definitely Not Checked Out Of His Job, To Host A Cooking Show [Techdirt]
RFK Jr. has a lot on his plate at the moment as the head of HHS. America is currently dealing with a record breaking outbreak of the measles, for instance. His agency has had a very hard time getting people confirmed for key roles. There’s that whole cyclosporiasis thing going around, which you’ll know you’ve caught it by the simple fact that you won’t be able to stop shitting yourself. There’s a huge self-inflicted talent vacuum at HHS and its child agencies. Pertussis cases are on the rise. Court orders keep blocking Kennedy’s committees.
With all of these crises and chaos, Kennedy became very angry at news reports that he was mostly checked out of the HHS work he should be doing to address all of this. It’s hard to take that anger all that seriously, though, given that Kennedy also became the very first sitting cabinet secretary to host a podcast while in office. And I have to assume it is also a first time a sitting cabinet secretary will — checks notes — host a cooking show with celebrity chefs.
Health and Human Services (HHS) Secretary Robert F. Kennedy Jr. has launched a show geared toward teaching Americans how to cook healthy, inexpensive meals.
“Thanks to President Trump, we flipped the food pyramid and put real food back where it belongs: at the center of the American plate,” Kennedy said in a video he posted Wednesday to YouTube touting “The Real Food Show.” “I’m traveling across America, connecting with renowned chefs to show families how to cook delicious, nutritious meals with real ingredients, and all at affordable prices,” the HHS secretary added. “America, it’s time to eat real food. Let’s get cooking.”
Cute. How about instead you travel the country on a mass vaccination campaign for measles? Maybe some lower level member of HHS can rub elbows with celebrity chefs while you, oh, I don’t know, do literally anything concrete when it comes to cyclosporiasis. Maybe you could fill the open roles in your agencies with competent people you can get confirmed by Congress. Or maybe you could get your agencies running smoothly and with high morale.
It’s not that cooking isn’t important. It’s not even that all of Kennedy’s thoughts on food and health are wrong, because they certainly are not. But there is other, real, important work that needs to be done, leadership that needs to be demonstrated, and confidence building that needs to happen with the public. All of that is a better place for the Secretary of HHS to be spending their time, compared with cosplaying as a daytime cooking show host.
Kennedy told USA Today his new cooking show aims to convince Americans that eating healthier does not cost more.
The price of food at home and away from home both rose by 0.2 percent from May to June, according to the consumer price index, a popular measure of inflation.
It’s actually worse than that and looking at the CPI for food on a monthly basis doesn’t tell the whole story. Year over year CPI for food is up by roughly 3%. All of that is to say that if Kennedy wants to focus on the affordability of fresh food, part of the solution would be for him to get his current boss to not play stupid games with tariffs and to stop starting the very foreign wars that he promised to keep us out of.
So, as you continue to see headlines for the very real health issues the country is currently facing, just remember that RFK Jr. is hard at work baking crab cakes and getting his plating skills just right.
10:00 AM
What Ukraine’s Battlefield Openness Can Teach Washington About AI Access [Techdirt]
On a laptop screen in a dimly lit tent near the Donetsk front, a Ukrainian drone team steers its aircraft into the turret of a Russian T-72 and glimpses the start of an explosion before the picture dissolves into static. The strike is uploaded, verified, and scored against the point value assigned to the tank. The unit climbs a public leaderboard that ranks hundreds of drone teams, and the points are currency: a higher score buys better equipment, faster, from an online marketplace the warfighters compare to Amazon.
Washington is about to decide how the federal government will parcel out access to the most powerful AI, and it is drifting toward concentrating that capability in a few chosen hands, rationed by criteria no one outside the process can see. A country with foreign invaders on its own soil has spent the past year learning to do the reverse—and winning back ground as it does. From Luhansk to Lviv, Ukraine puts its best tools in the hands of whoever can use them and shares what it knows about the enemy as fast as it safely can, openly and by rule.
Behind the leaderboard sits a set of arrangements Ukraine built under fire. A marketplace lets frontline units order drones directly from hundreds of manufacturers, most of them small shops scattered across Ukraine. A procurement cycle that once ran months now takes days, and new designs reach the trenches within about a month of leaving the workbench, because the units doing the fighting, not a distant acquisition office, decide what they need in the field. Furthermore, their feedback goes straight back to the manufacturer, sometimes the same day. Because the manufacturing is dispersed rather than massed, no single Russian strike could ever change much.
Ukraine has been just as willing to share what it learns. Late last month its defense ministry opened a platform called TrophyLab that hands the technical anatomy of captured Russian weapons—schematics, known vulnerabilities, even physical samples—to a deliberately wide circle: allied militaries and intelligence services, and hundreds of Ukrainian and partner-country firms. Access is vetted and revocable, governed by published criteria. The premise is that knowledge of a threat is worth more shared than hoarded. This should be a rule everyone can see, rather than the whims of a distant official.
That combination, wide but rule-bound, is exactly what the executive order the White House issued in June fails to deliver. Faced with AI systems that can now find software flaws faster than any human team, the order promises early access to the most capable models to a few “trusted partners”—a phrase it never defines, routed through a classified process. It calls the arrangement voluntary. In practice it has not been: under national-security and commerce authorities the administration has already restricted, suspended, and then cleared frontier models, with no published criteria anyone outside the process can point to. Ukraine’s leaderboard may be a crude way to run a war, but it is at least a rule—public, legible, the same for every unit.
The deeper problem is what that opacity does. Ukraine found that capability does the most good spread widely, that a defense holds because it has no single point of failure, and that threat intelligence should travel by rule rather than favor. A trusted-partner tier governed by undefined discretion inverts all three: it concentrates the best tools among those already best equipped, builds the very chokepoint Ukraine works to avoid, and turns shared knowledge into something rationed by judgment no one can inspect. The United States already runs sector-based centers for sharing threat intelligence; the question the framework raises is not whether to centralize but whether the flow reaches the defenders who need it or stops at a favored few.
And there are real lessons for the United States. Ukraine’s openness may look like the underdog’s strategy, and the United States is the wealthiest, most powerful country on earth—but national strength does not mean every system is strong. The defenders who most need help are not the money-center banks and wealthy university hospitals; they are smaller institutions that, despite non-specific promises they’ll be helped, seem unlikely to benefit from this system as it’s set up. For them, a head start reserved for the already-strong is no help at all.
Ukraine did not arrive at any of this by design. It was forced into it, and used a mix of openness and clear rules to stop a much larger power in its tracks. Washington has the luxury of choosing on purpose but may be drifting towards a system governed by whims and favoritism rather than clear rules and standards.
Eli Lehrer is president and co-founder of the R Street Institute.
Kash Patel Keeps Losing in Court [The Status Kuo]

FBI Director Kash Patel sure likes to sue others for defamation. Patel spent three years pursuing California blogger Jim Stewartson for $10 million, claiming he had defamed him. At one point, Stewartson referred to Patel as a “googly-eyed Kremlin bitch”—words that are now forever part of the official court record.
This week, Patel’s case against Stewartson fell apart. The reason presents a case study and a fine opportunity to learn about a topic that first-year law students all get to chew on: personal jurisdiction.
That’s a legal doctrine rooted in the Constitution’s guarantee of due process, and it limits a court’s authority to bind a particular party to its rulings. As we walk through this rather amusing case history, you’ll see how personal jurisdiction was Patel’s undoing, even as he sought to weaponize the court system and silence his critics.
It’s Schadenfriday, so enjoy this piece about how the FBI director blew yet another defamation case.
A default win in the wrong zip code
Patel and his nonprofit, the Kash Foundation, sued Jim Stewartson, a California-based writer who publishes the MindWar Substack, in June 2023. That was nearly two years before Patel was confirmed as FBI director.
Patel claimed in his complaint that Stewartson had made false statements about him on Elon Musk’s X platform between June 2021 and May 2023. Those statements included claims that Patel had attempted to overthrow the government, helped organize and plan the Jan. 6 attack on the Capitol, was guilty of sedition, was a Kremlin asset and had paid people to lie to Congress.
As Jay Willis, editor-in-chief of Balls and Strikes, pointed out in his write-up, the complaint didn’t stop at Stewartson’s posts about Patel. It characterized Stewartson as “habitually” defaming Patel and other “prominent conservative figures.” Stewartson also referred to Patel as a “chud”—a derogatory term that apparently needed its own Wiktionary citation in Patel’s complaint.

There it is, forever in the record.
Initially, and regrettably, Stewartson did not show up to defend himself. He later said he was never properly served and only learned about the resulting default judgment from a CNBC article. Whatever the reason, that nonappearance handed Patel a $250,000 default judgment in August 2025: $200,000 for Patel personally and $50,000 for the Kash Foundation. (Word to the wise: Don’t ignore a lawsuit, however baseless or frivolous, because it could result in a default that you then have to work hard to overturn.)
Stewartson finally got a lawyer, and he moved to set aside the default and to dismiss the case entirely for lack of personal jurisdiction.
In April 2026, Chief U.S. District Judge Andrew Gordon, an Obama appointee based in Las Vegas, found that Stewartson had not met his burden of showing that service of process on him had been inadequate. But, as Reason reported, the judge ordered briefing on whether the court even had jurisdiction to hear the case and what penalty, if any, Stewartson should face for his no-show if the court set aside the default judgment.
On July 25, Judge Gordon wiped that judgment off the books and agreed that the court lacked jurisdiction over Stewartson. Stewartson did not have sufficient “minimum contacts” with Nevada to establish the court’s power to force him to appear and answer. Simply put, Patel picked the wrong zip code to sue in.
Womp womp.
Now all Patel has to show for the case is a court record that preserves, for all time, what Stewartson called him. Stewartson broke the news of the dismissal himself, posting:
BREAKING: A Nevada federal judge has granted my Motion to Dismiss in the case of Kash Patel vs. Jim Stewartson. I’d like to commend the judge for including ‘googly-eyed Kremlin bitch’ in his ruling. Thanks to all for your support.
That’s the thing about high-profile defamation suits. The offending statements tend to get repeated and amplified whether they are true or not.
Personal jurisdiction, explained
So how did Stewartson escape the tightening legal noose Patel had thrown around his neck?
The question of “personal jurisdiction” is one of the thorniest—and, frankly, most sleep-inducing—aspects of civil procedure. But it is an important threshold question for any case. So take another gulp of coffee and follow along for a bit.
The controlling framework for personal jurisdiction traces back to International Shoe Co. v. Washington, a 1945 Supreme Court opinion establishing that a court can hear a case against someone only if that person has “minimum contacts” with the state where the suit was filed. That generally requires a real connection between the defendant and the state, so that it would be fair to drag the defendant into court there.
The Fifth and Fourteenth Amendments’ Due Process Clauses protect people from being bound by a court’s judgment unless they have fair warning that their conduct could land them there. The test asks whether defendants “purposefully availed” themselves of the forum state by doing something that shows they targeted that state, benefited from its laws or could reasonably anticipate being sued there. Absent that, hauling defendants into court would offend “traditional notions of fair play and substantial justice,” the standard set by International Shoe more than 80 years ago and still applied today.
This doctrine therefore protects against a particular kind of unfairness: a defendant getting sued anywhere a plaintiff happens to be, purely because that’s where the plaintiff experienced the alleged harm.
Whether a court has the power to hear a case is a very different question from whether the underlying claim has merit. A court lacking jurisdiction can’t reach the merits at all, no matter how strong or weak the case might otherwise be.
Lack of jurisdiction bit Patel in the ass
A judgment entered without jurisdiction isn’t merely wrong; it’s completely void, as though it never happened. That’s the mechanism that let Patel’s $250,000 win vanish entirely rather than be reduced or reversed on appeal.
Patel filed in Nevada because he lives there—and apparently still does, even though he is the FBI director and directors are normally based in D.C. But Stewartson lives in California. According to Judge Gordon’s order, Stewartson had virtually no connection to Nevada aside from attending a UFC event in Las Vegas back in 2016.
Patel’s lawyers argued that tagging Patel in posts, while knowing he lived in Nevada, constituted sufficient contact. Judge Gordon rejected that theory, writing that tagging Patel in posts unrelated to Nevada activities or entities does not target a Nevada audience, and therefore does not create a contact.
This makes sense. After all, if simply mentioning a public figure created jurisdiction wherever that figure lived, any public official could sue any online critic in his home state, and International Shoe’s due process protection would collapse entirely.
Judge Gordon further noted that Stewartson’s posts were aimed at the broader American political audience, not specifically at Nevada. Tagging a Nevada resident wasn’t enough on its own to create the connection to the state that the Constitution requires. And as Willis flagged, Judge Gordon noted that Patel’s team never alleged that even a single Nevadan had subscribed to Stewartson’s Substack or podcast.
Judge Gordon’s order never addressed whether Stewartson’s statements were true, false or protected opinion. So we may need to wait until another case to learn whether it’s defamatory to suggest Patel is a “chud” or a “googly-eyed Kremlin asset.” The order held only that Nevada lacked the constitutional connection needed to hear Patel’s claims, which meant the earlier default judgment was void from the start and had to be vacated.
But Judge Gordon did drop a hint about what he thought of that $10 million damages claim. In considering whether Patel’s reputation was actually harmed by Stewartson’s posts, he observed dryly:
(A)fter the defamatory statements, Mr. Patel was confirmed by the United States Senate as Director of the F.B.I. Clearly his reputation was not significantly sullied by the defamatory statements.
For his part, Stewartson doesn’t seem prepared to let things lie. Responding to a post by Patel, in which the director claimed, “The FBI had a severe loss of trust with the American people because of weaponization from the previous administration” and added, “We’re going after those who violated the law and their oaths,” Stewartson posted:
You were also going after bloggers. But you can’t even do that right. Suck it chud. We’re not done here.
A larger, familiar pattern
Stewartson wasn’t an isolated target. Patel has a habit of suing over things said about him online, stretching back years before he ever ran the FBI.
While serving as chief of staff to the acting secretary of defense, Patel filed a $50 million defamation suit against CNN and several of its reporters, alleging the network pushed “unfounded left-wing political narratives” portraying him as a Trump conspiracy theorist.
That CNN suit ended in a loss for Patel. The Fairfax County Circuit Court dismissed the case, ruling that, as a public official, Patel had failed to sufficiently plead that CNN acted with “actual malice” toward him—a standard set by the Supreme Court in 1964 in New York Times v. Sullivan. Patel appealed, and a divided Virginia Court of Appeals affirmed the dismissal in January 2025. The majority concluded that Patel’s allegations targeted CNN generally without meeting the specific pleading standard required. The panel’s ruling became something of a broader statement: Public figures suing the media for defamation lose most of the time, given the steep First Amendment hill they have to climb.
That wasn’t Patel’s only abandoned media fight from that era. He also sued the New York Times and Politico in 2019 over Ukraine-related reporting, then dropped both suits in 2021. Politico’s lawyers noted at the time that the judge had signaled he was preparing to toss the case.
The pattern resumed once Patel took over the bureau. He sued former FBI official and MS NOW analyst Frank Figliuzzi in Texas, after Figliuzzi joked on “Morning Joe” that Patel spent more time at nightclubs than at FBI headquarters.
Then, in April, Patel filed his most ambitious suit yet: a $250 million defamation action against The Atlantic and reporter Sarah Fitzpatrick over a story about his drinking and unexplained absences from the office. Jordan Rubin, who covers the case for MS NOW’s legal blog, noted the timing wasn’t a coincidence. Patel’s own complaint against The Atlantic pointed to the Figliuzzi litigation directly, arguing the outlet had been warned the drinking allegations “echoed a similar fabrication” from the Morning Joe segment, but published anyway.
The Figliuzzi suit didn’t survive: A day after Patel sued The Atlantic, a federal judge dismissed it, finding Figliuzzi’s comment, in context, could not have been understood by a reasonable person as a statement of actual fact about Patel.
The Atlantic suit revved up just days after the Stewartson dismissal. On July 27, The Atlantic moved to dismiss, arguing that Patel had not plausibly alleged actual malice in the article’s publication. The outlet’s brief didn’t hold back, stating flatly that Patel’s complaint “fails to state a viable defamation claim against Defendants.”
The Atlantic’s lawyers also used the filing to highlight Patel’s track record, noting that Patel has now filed five defamation lawsuits against media organizations in recent years and has yet to win one. They argued the pattern sends “an ominous message to the press: publishing reporting that he does not like comes at a high cost.” Editor-in-chief Jeffrey Goldberg added his own line in a public statement: “If Director Patel did not want to face this process, he should not have filed this suit.”
Patel isn’t backing down either. His attorney, Jesse Binnall, told Fox News Digital:
It’s truly incredible that The Atlantic wants one-sided discovery so that it can shield its own so-called ‘sources’ while being able to rummage through government documents unimpeded. This again shows that they are afraid of the truth and believe they are above the law. We intend to prove them wrong and bring accountability to the fake news.
That’s a lot of bravado given the legal scoreboard. The Atlantic is standing by its reporting, Patel’s other cases have gone nowhere, and Stewartson continues to taunt Patel online.
Patel ought to know that truth is a complete defense to defamation, which makes The Atlantic’s apparently well-sourced and corroborated reporting on his drinking a risky subject for a lawsuit where discovery will be quite broad. But he also ought to have known that lack of jurisdiction is a total bar to a complaint. Yet he plowed ahead anyway, only to run headlong into a legal wall.
Perhaps that explains the googly eyes?
08:00 AM
Ctrl-Alt-Speech: Zuck Starts Throwing His Weights Around [Techdirt]
Ctrl-Alt-Speech is a weekly podcast about the latest news in online speech, from Mike Masnick and Everything in Moderation‘s Ben Whitelaw.
Subscribe now on Apple Podcasts, Overcast, Spotify, Pocket Casts, YouTube, or your podcast app of choice — or go straight to the RSS feed. To get extended episodes with additional coverage, support us on Patreon.
In this week’s episode, Mike and Ben cover:
- The U.S. Is About to Design an AI Regulator. Here’s How to Get It Right (Council on Foreign Relations)
- Mark Zuckerberg Says U.S. Should Accelerate AI Development, Not Restrict It (WSJ)
- Want AI you can trust? Start by building the right institutions (Atlantic Council)
- Anthropic Says It’s Against A Ban On Open Weight Models. It Just Wants To Ban Everything That Makes Them Good (Techdirt)
- The High Stakes Behind the EU’s €890M Google DMA Fine (Tech Policy Press)
- Europe bears its teeth, political panic about OpenAI hack and YouTube refines partner policy (Everything in Moderation)
- Trump vows new tariffs on the E.U. after Brussels fines Google $1 billion (Qz)
And in the extended episode for Patreon supporters, they cover:
- Elon Musk’s xAI sues Minnesota over law banning ‘nudification’ technology (The Guardian)
- The Worst Person You Know Just Filed A Good First Amendment Lawsuit Against A Very Badly Drafted Nudify App Ban (Techdirt)
Our fun links this week are a replica of Scooby Doo’s Mystery-Machine and the Saltburn cricket scandal because we need more satire right now.
If you’re already a Patreon supporter, you can get the extended episode on Patreon.
07:00 AM

06:00 AM
Federal Judges Chastise Trump’s Justice Department For “Unlawful,” “Unethical” And “Unseemly” Conduct [Techdirt]
This story was originally published by ProPublica. Republished under a CC BY-NC-ND 3.0 license.
Across the country, federal judges are calling out Department of Justice lawyers, questioning in unprecedented ways whether they can be trusted to tell the truth or uphold centuries-old legal norms.
From Washington, D.C., to Rhode Island to Oregon, federal judges nominated by presidents from both parties, including Donald Trump, have zeroed in on what’s called “the presumption of regularity.” It essentially means that judges must presume that the government — whether it be federal prosecutors, an IRS auditor or an FBI agent — did their jobs according to the rules and in good faith.
Until Trump’s second term, which has seen an exodus of veteran DOJ lawyers and a transformative shift in priorities from issues like enforcing civil rights to instead defending a mass deportation agenda, this foundational tenet had rarely been discussed in federal courtrooms, former judges, lawyers and scholars say. But as Trump’s DOJ exhibits behavior that judges have called “unlawful,” “unethical,” “unseemly” or otherwise dishonest, adherence to that bedrock standard is now being questioned.
ProPublica reviewed hundreds of cases since Trump retook the White House in which judges criticized the actions of DOJ lawyers and found more than 40 in which they explicitly referenced the presumption of regularity. In many cases, judges have expressed frustration that they can no longer take the government at its word.
“Judges simply don’t believe the representations that are being made by United States attorneys, assistant United States attorneys and the like,” said John E. Jones, a former federal judge for the District of Pennsylvania, appointed by President George W. Bush.
“I don’t think in the annals of the Department of Justice, in the history of jurisprudence in the United States, we’ve ever seen anything close to this.”
In Rhode Island in May, Trump-appointed federal Judge Mary McElroy rebuked federal prosecutors’ conduct — saying they withheld information and misrepresented facts — as she quashed their requests for a subpoena in their investigation into a hospital’s care of transgender children. The judge alleged the DOJ had inappropriately claimed its investigation was operating out of Texas to secure subpoenas targeting sensitive medical records of patients in another state and that it falsely claimed the Rhode Island hospital hadn’t communicated with the department.
“The discrepancy between the honorable conduct expected of federal prosecutors and DOJ’s tactics in this case is unsettling,” McElroy wrote. “The Court cannot help but share the sentiment that ‘[t]he presumption of regularity that has previously been extended to [DOJ] that it could be taken at its word — with little doubt about its intentions and stated purposes — no longer holds.’”
Judges have emitted a chorus of condemnations against the legal basis for some of Trump’s political agenda, including the mass firings of federal workers, an immigration dragnet that has imprisoned hundreds of U.S. citizens and retribution campaigns against the president’s political enemies.
In doing so, federal judges are imbuing forceful language into their orders in a way that scholars say signals to the Trump administration that the third branch of government is losing trust in the Justice Department.
Federal judges rarely grant interviews, and none of the judges who criticized the Justice Department in their orders granted interviews to ProPublica.
In a statement, a spokesperson for the DOJ said its attorneys are “dedicated public servants who represent the United States with integrity, in accordance with their ethical obligations and the law.”
“The Department stands firmly behind the professionalism and good faith of its attorneys,” said spokesperson Kiersten Pels. The White House did not respond to a request for comment.
Federal judges have found that the government filed statements generated by artificial intelligence that referenced nonexistent case law, wrote briefs that ignored facts and filed declarations with inaccurate dates, the ProPublica review shows.
In one case, the government included documentation claiming a detainee had been convicted of marijuana possession in 2009. That detainee, the judge noted, citing what she called the government’s persistent “sloppiness,” would have been 4 years old.
“This Court will no longer blindly accept statements of fact from [the U.S. government] unless they are made under oath by an individual with personal knowledge,” Judge Christine O’Hearn, a President Joe Biden appointee, wrote in New Jersey while reviewing a writ of habeas corpus petition filed by a man who claimed he was unlawfully imprisoned by immigration officers. O’Hearn accused the government of defying her orders when, instead of releasing the man, Immigration and Customs Enforcement transferred him to a different facility in New York.
In Minnesota, the state’s top political leaders had publicly clashed with the administration following the violent ICE raids that led to the deaths of two U.S. citizens. Then the administration filed a flurry of subpoenas against them.
Last month, Judge Patrick J. Schiltz, who was appointed by George W. Bush and clerked for Supreme Court Justice Antonin Scalia, slammed the government’s actions and “spurious claims,” saying the presumption of regularity was being abused.
“Initiating a criminal investigation in order to harass political opponents or to coerce them into taking official action — particularly official action that the federal government cannot directly require those political opponents to take — is a blatantly unlawful and unethical use [of] the grand-jury process,” the judge wrote.
“Breakdown” of a Presumption
The presumption of regularity creates a high bar for those suing the government or defending themselves against it in criminal cases. They often must provide evidence that the government willfully violated a policy or otherwise deviated from its charge — that is, did something irregular — to overcome the standard.
It’s a shield the government wields often, with little notice, and one that is almost always successful. But overcoming that presumption has become increasingly common under Trump’s second term, according to court watchers.
About half of the cases ProPublica identified as questioning the presumption come from districts, including D.C., Maryland and Virginia, where by proximity and jurisdiction many of Trump’s actions are challenged and often heard by Democratic-nominated judges. The Southern District of New York, which has issued repeated rebukes of Trump administration actions, and the Northern District of California, another Democratic stronghold, are other hotbeds of judicial scrutiny.
Last September, D.C. District Magistrate Judge Zia M. Faruqui accused the administration of working around the federal grand jury process, getting an indictment from a state court after prosecutors had failed to get one in his court, which he called “unseemly,” if not “unlawful.” He fired off one of the earliest signs that the presumption itself could come into question.
“This only deepens the growing mistrust of the actions of prosecutors,” the judge wrote. “That is a sentiment that was once unthinkable, but the irregular is now the regular.” While the case was largely managed by assistant U.S. attorney Caelainn Carney, according to court transcripts, Faruqui was aiming his frustration at her bosses, including senior prosecutor Jonathan R. Hornok, and the leadership at DOJ. Neither attorney responded to requests for comment.
Pels, the DOJ spokesperson, told ProPublica that Faruqui “was wrong on the law” and noted that after the government appealed to the district’s chief judge, his order was overruled. “Judge Faruqui has a long-standing documented pattern of editorializing from the bench beyond the scope of the cases before him,” Pels added.
But in recent months, skepticism about the presumption has also come from judges appointed by Republicans, such as McElroy, or in GOP strongholds.
In Indiana, Trump-appointed federal Judge James Patrick Hanlon ordered the release of Salah Sarsour, president of the Islamic Society of Milwaukee and a lawful U.S. resident, from ICE custody in March. Sarsour’s lawyers argued the government had targeted him to suppress his First Amendment right to free speech. The DOJ invoked the presumption of regularity and argued his arrest was part of an anti-terrorism dragnet, which the judge threw out.
In the Southern District of Ohio, Judge Michael R. Barrett, appointed by George W. Bush, ordered ICE to release a detainee after concluding the presumption had been overcome because the government hadn’t presented a reasonable argument that the man was a flight risk.
News outlets, including CNN, have documented federal judges’ ire with Trump’s DOJ, and some of the cases under question have been well-publicized, such as the government’s illegal deportation of Maryland resident Kilmar Abrego Garcia to El Salvador. In that case, Judge Paula Xinis, a President Barack Obama appointee, criticized the government, saying, “You have taken the presumption of regularity, and you’ve destroyed it.”
Many of the rulings challenged one of Trump’s hallmark efforts: immigration enforcement and deportations.
“The presumption of regularity and integrity previously and routinely afforded to the Executive branch and the United States Attorney’s Office has been undeniably eroded in this jurisdiction and across the country,” O’Hearn wrote in February, noting that the federal government had repeatedly violated court orders in her district and others related to immigration operations.
In another immigration detention case, this one in Washington state, Biden-appointed Judge Lauren King said, “[t]he ‘presumption of regularity’ is dislodged here by the numerous factual errors in Respondents’ filings and by their conflicting representations.”
Jeremy Fogel, executive director of the Berkeley Judicial Institute and a former federal judge from California, said what’s happening in the courts feels more like a “political conflict” than the normal ebb and flow of the justice system.
“It’s really one branch that is really sort of questioning the legitimacy of the other one,” Fogel said. “I think the judges are trying to stand up for the legitimacy of their branch.”
Just Security, an online law and policy journal, has been tracking cases in which federal judges have admonished Trump’s prosecutors, including those involving the presumption.
“We’re witnessing a breakdown in the ways in which any administration ordinarily carries out its responsibilities, through the Justice Department in particular,” said Ryan Goodman, Just Security’s co-editor-in-chief.
Erosion of Trust, Ethics Inquiries
The erosion of trust from the federal bench comes as Trump has profoundly shifted priorities at the DOJ to align with his political platform: ending civil rights and diversity programs, deporting immigrants and stripping away environmental protections.
Those who deal with DOJ lawyers have noticed the difference in court.
Mitch Bernard, chief counsel at the nonprofit Natural Resources Defense Council, has faced off on environmental issues with the DOJ many times. Although they may disagree, he said, he always expected his opponents to be “fair and above board.”
That dynamic is gone, he said.
“I would call it a transformation of the role of the Justice Department,” he said. “There are many different judges in different jurisdictions not only ruling against the government but calling the government out for dishonesty and dissembling, and that’s an extraordinary thing.”
The result, Bernard said, is that “the government will lose more cases as a result of the way the Justice Department is behaving.”
Meanwhile, groups such as his are benefitting from the government brain drain. “We hired 10 litigating attorneys last year,” he said. Of those, eight came from the DOJ.
Judges aren’t just losing faith in the DOJ. Some are pushing to sanction Justice Department lawyers.
This month, Miami federal Judge Kathleen M. Williams ruled that Trump’s lawsuit against the IRS was an improper exercise in self-enrichment, citing the president’s lawyers for a series of misstatements in the case.
The Obama appointee referred the lawyer who brought the president’s case against the IRS, Alejandro Brito, to the Florida Bar for potential disciplinary proceedings. She also forwarded her ruling to disciplinary officials in New York, who had earlier received an ethics complaint about acting Attorney General Todd Blanche.
A DOJ spokesperson called the Blanche case “nothing more than a politically motivated bar complaint, filed by partisan activists who disagree with this Administration’s policies.” Brito did not respond to a request for comment.
In Rhode Island, McElroy referred DOJ lawyers to a review board for possible discipline for their handling of the hospital investigation.
“As citizens, we trust that federal prosecutors, when wielding this awesome power against a state, a company, or certainly against vulnerable children, will play fair and be honest with its counterparts and the judiciary,” McElroy wrote. “DOJ has proven unworthy of this trust at every point in this case.”
Daily Deal: The Lifetime Learner Bundle [Techdirt]
The Lifetime Learner Bundle feature access to uTalk and Stack Skills. Through uTalk, you’ll be able to speak keywords and phrases in no time and will start to see the results straight away. You can pick 6 languages to learn from their library of 140+ languages. You also get access to Stack Skills, the premier online learning platform for mastering today’s most in-demand skills. Take your love of learning to the next level with this bundle for only $40 for a limited time.

Note: The Techdirt Deals Store is powered and curated by StackSocial. A portion of all sales from Techdirt Deals helps support Techdirt. The products featured do not reflect endorsements by our editorial team.
Grand Jury Witness: Reflecting Pool Was Already Damaged Before Arrested Man Touched It [Techdirt]
Donald Trump swore he could turn the Lincoln Memorial Reflecting Pool into something he could use to bask in his own reflected glory. Instead, it turned out to be everything we expect from Trump: braggadocio followed by abject failure.
Trump hired some guys he used to do some stuff to his personal pool(s) back in the day. It was a no-bid contract — one that was immediately extolled by Trump as Great Stuff. According to Trump, his personal cabana boys could get the job done right, on time, and under budget.
None of that happened. His boys took to the pool repair, doing their level best to behave like government contractors. Trump then did a Glory Roll across the unfinished sealant with his motorcade to show off for the boys back at the White House. A week or so later, the pool was refilled. For a brief moment, it showed off the “American flag blue” Trump thought was missing from the original fixture. Then it turned into a blend of algae and peeling sealant.
Instead of pulling out his receipts and asking his pool boys whether this reflecting pool refurb was still under warranty, Trump claimed the floating chunks of blue sealant bobbing around in the green muck was the work of vandals. And, of course, he had political appointees willing to press this point on his behalf. Jeanine Pirro — the US Attorney for the District of Columbia — got right on it, arresting former Olympic canoeist David Hearn on felony vandalism charges.
Pirro alleged Hearn had damaged “two square feet of sealant.” Well, it takes $1,000 to make vandalism charges a federal felony. While this damage estimate is subject to federal no-bid contract markup, taking someone down for doing two square feet of damage is insane, especially when Trump is still out there claiming vandals cut a 150-350 foot gash into the pool sealant.
Trump also promised there was proof of his wild allegations — something that would presumably show up as the DOJ attempted to turn vandalism arrests into federal indictments.
Well, the DOJ managed to secure an indictment against David Hearn. And it managed to do this despite its own witness stating the pool was already fucked before Hearn decided to put his hands on end results of this damage:
A key grand jury witness in a case against a former Olympic canoeist accused of tampering with the Lincoln Memorial Reflecting Pool testified that the area was already damaged and would have required repairs regardless, lawyers said in a court filing Monday.
[…]
The witness, who is not identified, was the only person who testified about damages, and said that the property had already been damaged before, authorities say, Hearn stuck his hands in the water, according to Hearn’s team.
Now, for those of you unaware of how grand jury proceedings work (and especially for those MAGA folks who like to show up and be deliberately ignorant), we’ll break this down quickly. A grand jury is not like a regular jury. Its sole purpose is to decide whether or not the government has enough evidence to support an indictment. The accused person is not there, nor are they represented by the lawyers. This is completely non-adversarial. And YET, the government’s witness testified to the grand jury that the pool was already damaged before the accused even arrived on the scene of the alleged crime.
What’s absolutely wild is that the DOJ still got its indictment despite this damning testimony from its own witness. Welcome to Trump Town, I guess. But we’ll see how long this indictment lasts. Hearn’s legal reps have filed a motion demanding copies of grand jury documents because it’s pretty fucking clear some bullshit must have been pulled to get Hearn indicted even though a government witness testified that the pool was already in shambles.
Lawyers for David Hearn, a 67-year-old who represented the United States at three Olympic Games, submitted a court filing seeking access to transcripts of the grand jury testimony as well as the instructions given to the panel that ultimately indicted Hearn, claiming that there were “irregularities” in the proceedings that led to the indictment.
[…]
In the filing, Hearn’s legal team suggests that the jury was not “properly instructed” on the crime Hearn stands accused of, noting specifically that felony destruction of property requires the perpetrator to have caused $1,000 or more of damage. The attorneys pointed to the testimony of the federal government’s own witness, an official from the National Park Service, who suggested that the pool was damaged long before Hearn interacted with the pool and that repairs were already being sought.
The full filing [PDF] by Hearn’s legal team is embedded below. It’s worth a read. And I certainly hope the judge grants this motion because if it contains the sort of stuff these accusations suggest it the documents might contain, this won’t be the first time the Trump administration has been caught cheating even though the process already allows the government to put its prosecutorial thumb on the scales.
12:00 AM
Trump FCC Hilariously Bungles Chinese ‘Drone Ban’ [Techdirt]
Earlier this week we noted how the Trump administration’s unpopular ban on Chinese drones had become a crony capitalist mess, with Brendan Carr and his FCC struggling to fine or ban companies for violations. The ban is a stupid, protectionist mess that has far more to do with coddling the president’s sons’ drone investments than it does protecting national security or consumer privacy.
Right on queue, The Verge has an interesting feature on just how easy it has been for some companies to bypass the FCC restrictions. The Trump ban was supposed to encourage drone makers to create devices here in the U.S.; but instead companies are simply setting up the laziest fake companies in the U.S, and the Trump FCC appears too short-handed or incompetent to notice.
So the over-arching impact of the ban has been to create a flood of new companies selling popular DJI-made Chinese drones under a litany of new names. They don’t try very hard to disguise them:
“When software developer and journalist Konrad Iturbe began watching FCC databases for those frequencies, he realized that DJI was preparing to play a grand game of Whac-A-Mole in the United States. Well ahead of the December 2025 drone ban, a host of new companies had suddenly appeared selling barely disguised versions of DJI technology. He dubbed them “DJI front companies.”
To pretend these drones are made in the U.S., the companies use fake U.S. front locations to pretend that the drones are assembled here. Again, they’re not trying very hard to disguise them, and most could have been unearthed with basic Google searches:
“But it’s easier than that. Odyssey Robot declared that its drone was designed, developed, and manufactured at 21 Miller Alley Suite 210 in Pasadena, California. Even a basic Google search can show you that’s not the address of a factory — it’s a coworking space called Industrious that explicitly prohibits members from manufacturing anything onsite.
Odyssey Robot also declared that its drones are assembled at eTak Worldwide Corporation in Grand Prairie, Texas. With 80,000 square feet of warehouse space and 15 loading docks, you could theoretically build drones there. But again, a basic Google search would show you that eTak isn’t an assembler; it’s a recycling company that collects e-waste, including old batteries, then sorts and dismantles them.”
Like most of what Trump does, none of this appears thought out very well, and the administration isn’t competent enough to even do basic investigations to enforce its own restrictions. And like elsewhere in the administration, Trumpism rejoices at the idea of dismantling regulators; then throws these weird sorts of complicated demands in their lap expecting productive outcomes.
Again, in a functional world, you’d allow Chinese companies to do business in the United States, but you’d fund, staff, and legally empower your regulators to strictly enforce competition, labor, environmental, and consumer protections. Because that would result in U.S. companies making less money and having to try harder, we instead get this weird jumbled tangle of corruption and buffoonery.
The primary justification for the Trump Chinese drone ban is that these devices pose meaningful privacy and national security risks. But there’s been absolutely no evidence presented by the administration supporting this allegation. There is, however, ample proof that administration greed, corruption, and incompetence has been indistinguishable from a foreign attack.
John Oliver Dares Buc-ee’s To Sue Him Over Trademark Infringement [Techdirt]
I will admit it’s always a special kind of fun when a topic we cover here at Techdirt gets the John Oliver treatment. He and his writing team generally gets things right, which helps. And I’m not saying that Oliver and his crew are definitely Techdirt readers, but, well, hi John and crew!
Readers here will recall that I’ve spent the last year or so pointing out that famed gas station and/or supermarket chain, Buc-ee’s, has become the trademark bullying Monster Energy of gas stations. This is a company that doesn’t seem to understand what parody is, and which somehow believes that it alone owns the right to use a cartoon animal, or sometimes human, in a circular logo for any kind of related business to its own.
Well, Oliver dedicated a segment to Buc-ee’s bullying ways on his show this past week and he did not disappoint.
In recent years, it sued Super Fuels in Dallas, whose logo was a brown dog sporting a red cape, a drive-through liquor store in Missouri named Duckees featuring a cartoon duck wearing sunglasses, Choke Canyon Travel Center in Texas over its cartoon alligator wearing a cowboy hat, and Nut Huggers, an Oklahoma-based underwear company with a mascot of a squirrel.
Oliver accused the chain of “outright bullying,” noting that most of the stores have changed their logos because they do not have the resources to fight the Texas giant, which operates more than 50 stores.
And that’s where the real fun starts.
Now, it would be absolutely stupid for Buc-ee’s to actually sue Oliver and HBO over this. The PR would be terrible, it would only give Oliver more attention and generate more headlines about the company being a trademark bully, and it would make the company look very thin-skinned and childish. I’m also relatively certain that’s exactly what will happen.
After all, any such lawsuit wouldn’t even rank in the top 3 of stupid trademark suits that Buc-ee’s has filed. And since they’ve demonstrated that they just can’t help themselves, I imagine we’re going to get more segments about this on Oliver’s show.
Axon Insists Its AI Makes Police Reports Easier. Nothing Suggests It Makes Them Any *Better* [Techdirt]
It’s not that AI can’t be useful or helpful in certain contexts. And this is certainly not to say AI can’t take over repetitive tasks to allow people to focus on things that need more of human touch.
The problem with AI isn’t necessarily AI itself. It’s that far too many tech companies are pitching AI as a one-size-fits-all solution to pretty much everything. And far too many entities are taking tech companies at their word, with disastrous results.
Axon (formerly Taser) has cornered the body cam market and is now trying to sweep up everything else. While it still hasn’t made a foray into facial recognition tech, it’s pitching products (Draft One and Form One) that use AI to automate report writing for police officers. Draft One has been pitched as a time-saver — one capable of transcribing body cam audio to generate police reports. The company’s CEO Rick Smith thinks this add-on to its body cam products with “potentially free up 25% of an officer’s time.”
Considering a lot of officers spend most of their time engaged in pretextual stops, this isn’t really good news. It just means officers will be able to violate rights more frequently with no perceivable benefit to public safety.
Then there’s the problem AI companies just can’t seem to solve, like extremely vivid hallucinations:
An artificial intelligence that writes police reports had some explaining to do earlier this month after it claimed a Heber City officer had shape-shifted into a frog.
However, the truth behind that so-called magical transformation is simple.
“The body cam software and the AI report writing software picked up on the movie that was playing in the background, which happened to be ‘The Princess and the Frog,'” Sgt. Keel told FOX 13 News. “That’s when we learned the importance of correcting these AI-generated reports.”
Weirdly, this anecdote comes from the same law enforcement agency that claims AI-generated police reports keep this Utah city “safer.” The report doesn’t explain how this is being accomplished. Sgt. Keel simply says the tech saves him “6-8 hours a week.” Sgt. Keel does not explain what’s being done with these extra hours.
The other problem with relying on AI to generate police reports is that officers are generating a new layer of plausible deniability. If errors are found, cops can blame it on the algorithm. Beyond that, there are problems cops pretend don’t exist, like making any testimony reliant on AI-generated reports instantly suspect. If cops aren’t writing their own reports, they can’t possibly claim these statements are their own under oath.
But even if you ignore all of that and choose to focus on the things companies like Axon would prefer you to direct your focus to, we’re still not seeing the sort of improvement that would theoretically offset the downsides of relying on AI. Trial runs of Axon’s new Form One AI product haven’t exactly been a resounding success, as Thomas Brewster reports for Forbes.
[A]fter seven months of testing the technology, many of Lafayette’s officers found the tool was wasting time, not saving it. “I know it doesn’t save me time and I know it has inaccuracies that I will have to edit,” wrote one officer in a cache of emails obtained by Forbes via public records request. Form One struggled to record the right names or car plates, even when they were clearly stated in the camera footage, according to other emails. One cop said a simple form that used to take 30 seconds to fill out manually now takes three minutes with Form One because there are so many errors. “Form One dramatically increases the time it takes to finish reports,” he wrote to a colleague.
That’s just the experience of a single town of 70,000 people in Indiana. Imagine having this amount of routine failure applied to departments with hundreds of officers and thousands of daily reports. What’s worse is that Form One is far less sophisticated than Draft One, which is used to transcribe body cam footage. The software is only expected to accurately add names and addresses to relevant sections of police reports. If it can’t be trusted to do this, there’s little reason to believe Draft One can provide an accurate accounting of a police stop by transcribing audio.
Axon claims these are not indicative of whatever the final product will be. According to the Axon spokesperson, Lafayette was granted “early access” to an (apparently) unfinished AI tool. Axon implies the final product will be better, but neither the Lafayette PD or Axon itself were willing to provide any info that might allow critics to move this from implication to inference.
Manchester, New Hampshire’s police department had roughly the same experience with Draft One.
Ian Adams, a former police officer and criminology professor at the University of South Carolina, studied the Manchester Police Department in New Hampshire’s use of Draft One. Adams analyzed time stamps for when officers started a report and when they filed it. Only some had access to the software. The study found that there was no improvement in how long it took for cops to file reports because they spent a significant amount of time editing the AI system’s work: removing irrelevant information, fixing inaccuracies and adding important facts it missed. “It was just easier to type the report themselves,” says Manchester’s Lieutenant Matthew Barter, who participated in the research.
Weirdly, most officers still thought Draft One sped up report writing, despite data showing otherwise. And even if officers were convinced Draft One was more efficient that simply writing reports themselves, the PD apparently decided the data was more accurate than a bunch of subjective opinions. And it wasn’t the only beta tester (so to speak) to do so:
Even though it was the first agency to test Axon’s Draft One, Manchester ditched it in 2024. The same year, the Anchorage Police Department in Alaska also decided to stop using it, citing zero time savings.
Presumably, these agencies weren’t required to pay for this subpar tech. And while it’s safe to say the tech will continue to improve, the question is whether it will ever be worth it. With fewer courts willing to accept AI-generated court filings and becoming increasingly skeptical of the tech in this context, cop shops are going to be paying for a product that generates reports they can’t submit as testimony or evidence.
Beyond that, the tech apparently needs so much human backstopping that the job of writing reports may as well just be handed back to the humans. Even if it does improve to the point that it can actually reduce the paperwork load on officers, no police department enthused about the tech has specified what will be done with all of this new free time. If it’s just going to be more of the same old policing, the public gains nothing but additional chances to have their rights violated. If the free time is going to be used to build community relationships and route more officers to investigations that might contribute to overall public safety, some sort of trade-off might be acceptable. But from what’s been demonstrated so far, AI is just compounding errors without providing any real usefulness to the communities these law enforcement agencies serve.
Daily Deal: Build A Weather App With Ruby On Rails [Techdirt]
It’s time you get up to speed with Ruby on Rails! This full-stack web framework is all about letting you build applications quickly. Its elegance, flexibility, and speed make Ruby on Rails a popular choice for businesses, so taking the time to master it can pay huge dividends down the road. In this course, you’ll follow along with the instructor as he uses Ruby on Rails to create an ozone air quality monitoring weather app. You’ll understand Ruby on Rails in just two hours and know how to use it to build awesome web apps. It’s on sale for $20.

Note: The Techdirt Deals Store is powered and curated by StackCommerce. A portion of all sales from Techdirt Deals helps support Techdirt. The products featured do not reflect endorsements by our editorial team.
The Worst Person You Know Just Filed A Good First Amendment Lawsuit Against A Very Badly Drafted Nudify App Ban [Techdirt]
There’s been a bunch of news this week regarding Minnesota’s new law that purports to prohibit “nudification” technology, and the fact that xAI has sued to have the law blocked as unconstitutional. A few things need to be said upfront, because it’s very, very easy to just say the tech is terrible, that Elon Musk and Grok are terrible, and that of course Minnesota should ban it. But it’s also possible that, in the rush to attack very problematic apps built by very problematic people, Minnesota drafted a bad law that is ridiculously overbroad and pretty clearly unconstitutional. And… that is exactly what appears to be the case.
Let’s start with the basics: apps (mostly powered by various AI tools) that are used to produce modified imagery, especially stripping people of their clothes are… bad. They should be socially shunned. People using them to objectify or sexualize others are doing bad things, and people should judge those who use those apps accordingly. This is not a defense of those apps. Similarly, Elon Musk’s Grok and its widely promoted use of putting people (including children) in bathing suits definitely deserves social shunning as well. Norms take time to form, and the shunning here is still catching up to the technology.
But passing a badly drafted, obviously unconstitutional law does not help form those norms. Nor does it punish Elon Musk. Instead, it allows him to act like a First Amendment martyr.
It’s also worth clearing something up early, because a lot of the coverage has gotten it wrong: this is not a law about child sexual abuse material. CSAM is already quite illegal under both state and federal law, and nothing in HF 1606 is limited to images of minors. Had Minnesota drafted a law narrowly targeting AI-generated CSAM, it might have survived a constitutional challenge. That’s not what it did.
And if you want to pass a law to ban technology like this, there are rules under the First Amendment. And, in Minnesota, we even know what some of those rules are. After all, a decade ago, the state also passed a law criminalizing the dissemination of “nonconsensual private sexual images.” After some back and forth in the courts, the Minnesota Supreme Court finally blessed the law as constitutional in late 2020, but made it quite clear that the law went right up to the First Amendment line. It first noted that while the state wanted to claim there’s an entirely new category of unprotected speech (in this case, “substantial invasions of privacy”), the court refused to do so, citing the famed US v. Stevens case (about an attempt to outlaw animal “crush” videos) in which the Supreme Court made it quite clear that it wasn’t open to creating new categories of unprotected speech:
The United States Supreme Court has emphatically rejected “freewheeling” attempts “to declare new categories of speech outside the scope of the First Amendment.” Stevens, 559 U.S. at 472; see also Jorgenson, 946 N.W.2d at 604 (“The United States Supreme Court has been reluctant to expand these traditional categories of unprotected speech.”). It is possible, however, there are “some categories of speech that have been historically unprotected, but have not yet been specifically identified or discussed.” Stevens, 559 U.S. at 472.
To successfully argue for a new unprotected category of speech, the proponent must present “persuasive evidence that a novel restriction on content is part of a long (if heretofore unrecognized) tradition of proscription.” Brown v. Ent. Merchs. Ass’n, 564 U.S. 786, 792 (2011). This is a heavy burden to bear, and the Supreme Court has recently rejected creating new categories of unprotected speech for animal cruelty, Stevens, 559 U.S. at 472, depictions of excessive violence, Brown, 564 U.S. at 791–93, and false statements, Alvarez, 567 U.S. at 722–23.
In this case, we conclude that the State has failed to carry the heavy burden required to provide a basis to establish a new category of unprotected speech.
And yet, the law was still deemed constitutional, but not because it created a new category of unprotected speech, but rather because it passed strict scrutiny, in which the law is narrowly tailored to use “the least restrictive means” of addressing a compelling government interest. That is the test by which a law can still be deemed viable under the First Amendment, despite suppressing speech. In the case of the nonconsensual imagery bill, the law passed strict scrutiny because it focused very narrowly on a category of speech that is very likely to cause harm, and put in place a law that was narrowly tailored to only target that speech, and on top of that included clear exemptions for edge cases that likely wouldn’t be harmful.
Indeed, the court leaned hard on the fact that the law only reached images disseminated without consent, and only when the disseminator knew or reasonably should have known the subject expected privacy. Those two limits — consent and intent — are what kept the statute from sweeping in vast amounts of protected speech. Some quotes from the court which list out all the factors necessary to pass strict scrutiny.
First, the Legislature explicitly defined the type of image that is criminalized…. Furthermore, the image has to be “obtained or created under circumstances in which the actor knew or reasonably should have known the person depicted had a reasonable expectation of privacy.” Id., subd. 1(3). Images that do not clear each of these hurdles fall outside the scope of the statute.
Second, a defendant must “intentionally” disseminate the image. … This mens rea requirement means that a defendant must knowingly and voluntarily disseminate a private sexual image; negligent, accidental, or even reckless distributions are not proscribed. This specific intent requirement further narrows the statute and keeps it from “target[ing] broad categories of speech.”
Third, the statute has seven enumerated exemptions…. The statute allows for private sexual images to be distributed “in the course of seeking or receiving medical or mental health treatment.” Id., subd. 5(3). Advertisers, booksellers, and artists are protected because images “obtained in a commercial setting” for legal purposes fall outside the statute’s reach. Id., subd. 5(4). Journalists cannot be prosecuted because there are exemptions for the dissemination of private sexual images that involve matters of public interest and “exposure[s] in public.” Id., subd. 5(4)–(5).8 Educators and scientists are protected because there is an exemption for private sexual images disseminated for “legitimate scientific research or educational purposes.” Id., subd. 5(6). Accordingly, even if protected speech falls within the ambit of subdivision one and a disseminator acted with the requisite mens rea, that person may still be exempt from prosecution under these precise exceptions.
Fourth, to be prosecuted under the statute, a disseminator must act without consent…. This provision provides additional protection for commercial advertisements, certain adult films, artistic works, and other creative expression outside the statute’s scope.
Finally, this statute only encompasses private speech…. Unlike the overly broad statutes at issue in our recent decisions in In re Welfare of A.J.B. and Jorgenson, this statute covers only private sexual images and does not prohibit speech that is “at the core of protected First Amendment speech.”
It was all of that combined that allowed the law to pass strict scrutiny — something that is incredibly difficult to do. Most laws that have to clear strict scrutiny don’t. Here, this law survived with a careful roadmap from the court of how to do so.
One would think that Minnesota legislators would be aware of this ruling and the clear reasons why the law was deemed to pass strict scrutiny and then write an equivalent law with the same elements in trying to ban nudify apps.
But for reasons known only to the Minnesota legislators, they basically ignored every single one of those points.
Minnesota’s anti-nudification tech law is not limited to non-consensual content. This means, as legal commentator Kathryn Tewson noted, that if she uploaded a picture of herself and asked Grok to put her in a bikini, she could by her own hand, cause Grok to break this law. That… seems like a very problematic law.
And, again, the Minnesota Supreme Court has already told the state pretty much exactly how to make this law constitutional: focus on nonconsensual imagery, narrowly tailor it to just the deeply harmful content, include an intent requirement, and include clear delineated exemptions for things that should be allowed.
Minnesota legislators did none of that. Indeed, even the definition of “intimate parts” in the law borrows its definition of ‘intimate parts’ from an earlier statute, covering: “the primary genital area, groin, inner thigh, buttocks, or breast of a human being” — not much of which is inherently sexual, let alone harmful. Tewson offers another example: an edit of a Taylor Swift photo that changes the texture of her fishnet stockings to look more like skin. Whatever tool made that edit just violated Minnesota law.
This is, by definition, an overly broad, non-narrowly tailored law.
Another example: last year the TV show South Park did a deepfake parody of Donald Trump, showing a photorealistic version of him wandering naked through the desert, including his “intimate parts.”
Under this law, that video could violate HF 1606. That’s not narrowly tailored. That’s not dealing with intent or focused just on truly harmful content.
One lawyer I spoke to, after reading through the statute, wondered out loud whether the Minnesota legislature had deliberately drafted it in the dumbest way possible just to guarantee a successful challenge. That’s how poorly the law was drafted.
Of course, no one wants to hear that the law is badly drafted. Lots of people want to ban nudify apps and to yell about how ridiculous it is that Elon Musk has gone to court to challenge this law.
But… it’s the sort of thing he should be doing. Otherwise anyone can have Grok put themselves in a bikini and… Minnesota’s Attorney General can demand $500,000 for each such image created, even when the image was created deliberately, by the person in it, of themselves.
xAI (now a division of SpaceX) is right to challenge the law, not because nudify apps are a good thing, but because the law is terribly drafted and pretty clearly exceeds what’s allowed under the First Amendment. The complaint itself is worth a read. For one thing, it explains why xAI last week sued one of its own users for producing CSAM with Grok (which I had found perplexing at the time). It reads a lot like the company wanted a concrete example to put in this filing of how it fights back against those who use Grok in such ways (leaving out, of course, that Elon himself used the app to put himself in a bikini, thereby encouraging others to do the same).
It also explains why that complaint was focused on triggering the indemnity clause in X’s terms of service, which makes the user liable for any legal costs associated with their use of the product. What Musk is really signalling with that lawsuit is if Minnesota’s AG sues us under this law for your usage of the product, we’re going to sue you to cover our costs (which could include the $500,000 fine for any images created).
As the lawsuit notes, the law is just terribly written:
HF 1606 punishes AI platforms that allow users to alter images of real people to depict an “intimate part.” But the statute contains no knowledge, intent, or purpose requirement. It is a strict-liability statute keyed solely to whether a user succeeded in creating a covered image using the AI provider’s platform—regardless of whether the provider prohibits users from using its tool for such a purpose, regardless of how many mitigations the provider has in place, and regardless of how diligently the provider polices such conduct using its tool. There is no safe harbor for good-faith efforts of the provider of general-purpose AI creative tools to avoid harms. Liability attaches even if the depicted persons consented—or created the image themselves—and even if the image is never shared. Liability also attaches even if the image has artistic, scientific, political, satirical, educational, medical, or religious value, and (again) even if the company has deployed near-perfect, state-of-the-art technical controls to prevent the generation of nude images.
Additionally, the law’s definition of “intimate part” is exceptionally broad. Although the federal government and various states have enacted statutes that clearly define nudity for the specific context of AI-generated images, Minnesota rejected such a precise definition. Instead, it borrowed the definition of “intimate part” from a criminal sexual-contact statute. That definition was drafted for nonconsensual touching and thus covers the inner thigh, buttocks, or breast of a man or woman, as well as the groin and primary genital area. HF 1606 accordingly bans ordinary depictions of men without shirts, people in shorts or swimsuits, and other body parts routinely displayed in public—far beyond what an ordinary person would consider “nudification.”
Even worse, as the lawsuit states, the bill’s “principal sponsor” admitted that the law was designed to apply to consensual imagery:
A service used by an adult to edit a photograph of him or herself or a consenting individual is covered on the same terms as a service used to create an image of an unwilling stranger. The statute’s text draws no distinction among them. And this was by design. When a staff member of the Senate Judiciary and Public Safety Committee pointed out that the Act’s “prohibition applies to consensual images,” Senator Maye Quade (the bill’s principal sponsor) explained “that is intentional.”
That is the bill’s main sponsor stating, on the record, that she deliberately chose to leave out one of the very features Minnesota’s own Supreme Court had identified as necessary for a law like this to survive constitutional scrutiny.
That is legislative malpractice.
Since the lawsuit was filed, Maye Quade and other legislators have publicly defended the bill:
“I don’t see this as a free speech issue. This does not regulate content; it does not regulate art. It regulates conduct,” Maye Quade said. “Prompts are not art, and we protect art specifically in this law. It’s pretty audacious to sue to prevent a law that protects children from being turned into child sexual abuse material.”
She’s describing a law she could have written, but didn’t.
Notice what’s missing from that defense: any explanation of why the consent and intent elements the Minnesota Supreme Court specifically identified as saving the 2016 law were left out of this one. Also, she’s just simply incorrect that the law does not regulate speech. Again, if she simply read what the Minnesota Supreme Court said about the nonconsensual intimate imagery law, it spent pages analyzing the nonconsensual imagery statute — a law covering narrower material than this one — as a content-based restriction on speech that had to pass strict scrutiny to survive.
Similarly, the law does not actually “protect art.” Its one and only exemption is if the work “requires the technical skill of a user to nudify an image or video.” That could protect some art, but not all. And it defines art only in a case where a level of skill is needed, which itself potentially creates First Amendment issues in defining what is, and what is not art. There is plenty of modern art that people regularly complain takes no “technical skill” to create.
The complaint itself includes some other examples of what would violate the law, including this (gross) AI-generated image that Trump posted of a slimmed down version of himself, some of his cabinet members, and a randomly generated woman in a bikini sitting in a gleaming blue reflecting pool. Under the law, whatever tool was used to generate that image pretty clearly violated Minnesota’s law:

{kind=link}
In this viral snapshot—which President Trump posted publicly— President Trump, Vice President J.D. Vance, Secretary of State Marco Rubio, and Secretary of the Interior Doug Burgum all are portrayed shirtless in the Washington Mall’s reflecting pool, along with an unknown (possibly fictitious) woman.19 An “intimate part” (the breast) of at least the President, Vice President, Secretary of the Interior, and the woman are “depict[ed],” with the Secretary of State also at least arguably included as well. The President posted this image on his personal account, presumably to make light of the public controversy surrounding repairs to the reflecting pool on the National Mall.
Nudify apps are gross. Musk’s encouragement of people to use Grok to de-clothe people is gross. People who use AI tools to “nudify” people are gross. But that doesn’t mean all laws targeting such things are good laws or constitutional.
In this case, despite having clear instructions from its own Supreme Court on how to write a constitutional law, Minnesota’s legislature deliberately chose to write an unconstitutional one. And thus, this lawsuit is the proper thing for SpaceX/xAI/Musk to do.
Supporting the lawsuit is not supporting Elon or Grok or nudify apps. It’s telling every legislature in the country the same thing: if you want the law to survive, learn to draft it in ways that aren’t unconstitutional.